Google unveils phenomenal new Lumiere video creation AI
Google Research Lumiere
Google Research Lumiere
A Space-Time Diffusion Model for Realistic Video Generation
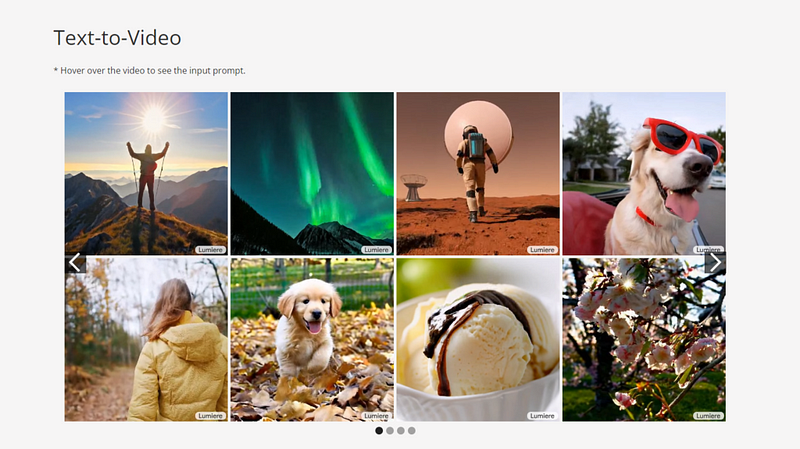
Google AI has launched Lumiere — a text-to-video diffusion model designed specifically for synthesizing videos showing real, diverse and coherent actions. The effect in video synthesis is amazing: including image-to-video conversion, video restoration and stylized generation, Products that surpass runway, pika and SVD seem to be not far away.
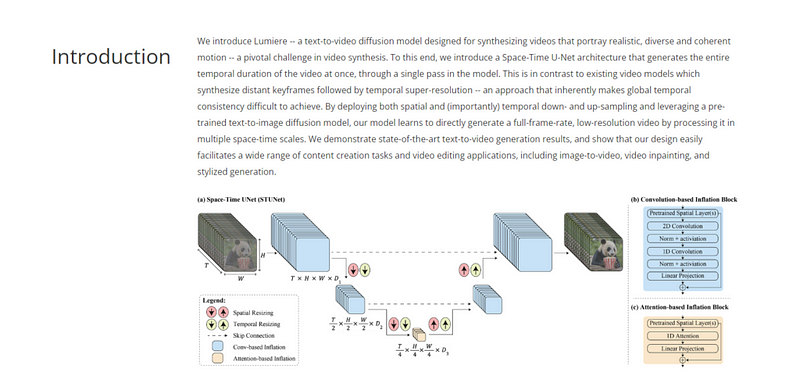
To achieve this, Google AI introduces a spatiotemporal U-Net architecture that is able to generate the entire time span of a video in a single pass of the model. This is different from existing video models, which typically synthesize keyframes first and then perform temporal super-resolution, an approach that inherently makes achieving global temporal consistency difficult.
By implementing spatial and (importantly) temporal downsampling and upsampling, and leveraging a pretrained text-to-image diffusion model, Lumiere learns to process video at multiple spatiotemporal scales, directly generating full frame rate low-resolution video. .
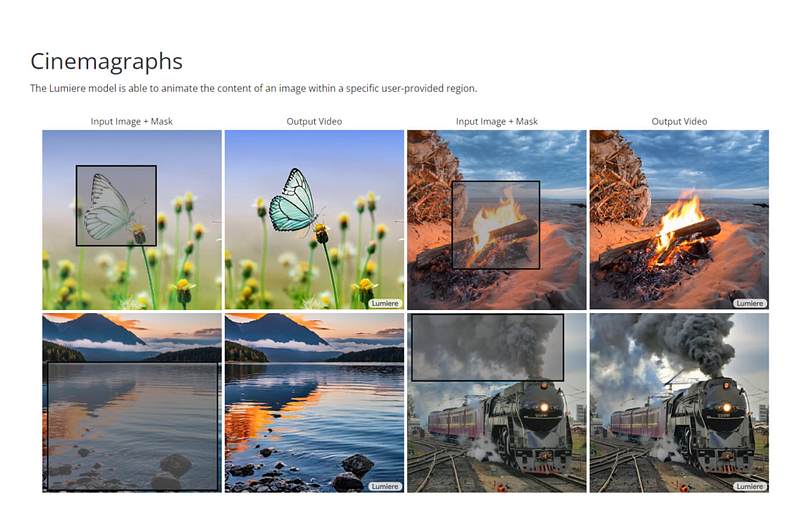
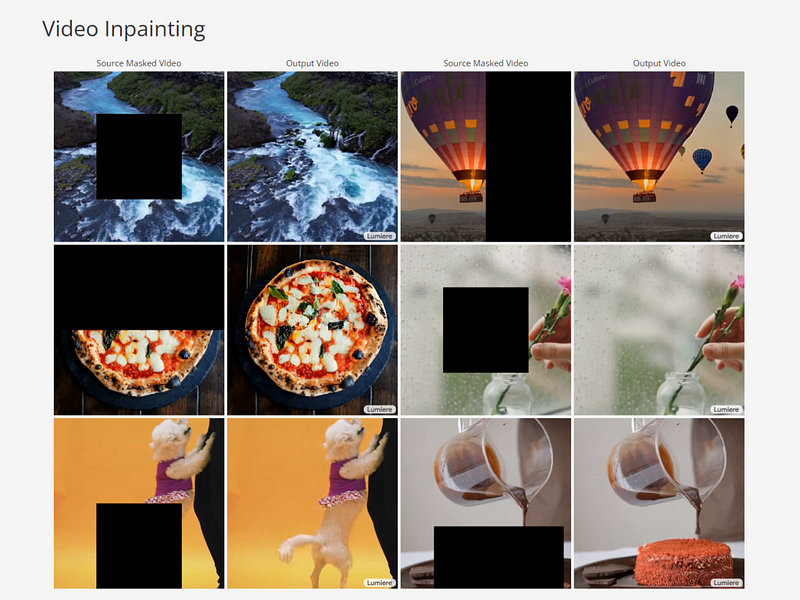
As you can see from the demo above, Lumiere has the most advanced picture-in-video feature we’ve seen to date. All you have to do is paint in the parts of the frame you don’t like, and Lumiere will automatically fill in the area with such a beautiful effect that you might not even notice if you’re not looking carefully. Ex-boyfriend shows up in your favorite video? It won’t be long.
The relevant research team stated that Lumiere’s “spatio-temporal U-shaped network architecture” can construct the entire length of the video at once — while previous models usually generate the start frame and end frame first, and then guess what will happen in the middle.
No matter how you do it, the results speak for themselves — this is the new state of the art in generative AI video.
Text-to-Video
Image-to-Video

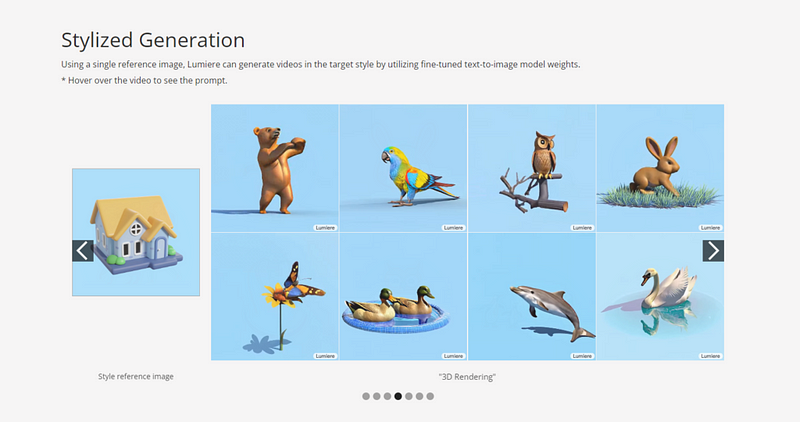
Stylized Generation
Introduction
We introduce Lumiere — a text-to-video diffusion model designed for synthesizing videos that portray realistic, diverse and coherent motion — a pivotal challenge in video synthesis. To this end, we introduce a Space-Time U-Net architecture that generates the entire temporal duration of the video at once, through a single pass in the model. This is in contrast to existing video models which synthesize distant keyframes followed by temporal super-resolution — an approach that inherently makes global temporal consistency difficult to achieve. By deploying both spatial and (importantly) temporal down- and up-sampling and leveraging a pre-trained text-to-image diffusion model, our model learns to directly generate a full-frame-rate, low-resolution video by processing it in multiple space-time scales. We demonstrate state-of-the-art text-to-video generation results, and show that our design easily facilitates a wide range of content creation tasks and video editing applications, including image-to-video, video inpainting, and stylized generation.
Video Stylization

Cinemagraphs
Video Inpainting
Authors
Omer Bar-Tal*,1,2Hila Chefer*,1,3Omer Tov*,1Charles Herrmann†,1Roni Paiss†,1
Shiran Zada†,1Ariel Ephrat†,1Junhwa Hur†,1Yuanzhen Li1Tomer Michaeli1,4
Oliver Wang1Deqing Sun1Tali Dekel1,2Inbar Mosseri†,1
1Google Research
2Weizmann Institute
3Tel-Aviv University
4Technion
(*): Equal first co-author, (†) Core technical contribution
Work was done while O. Bar-Tal, H. Chefer were interns at Google.